Semaine exotique 4
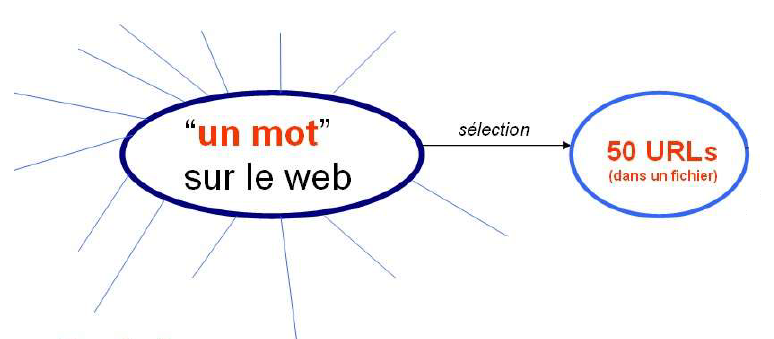
Lors de la préparation d’un nuage de mots, on a remarqué que…

Il y a des mots qui sont comptés plusieurs fois différemment. S’agit-il des caractères différents ?
L’éditeur hexadécimal indique qu’ils sont bien identiques.
L’exécution de cette opération en partie a révélé le problème derrière ce phénomène.
Problème du japonais : Le système d’écriture est complexe.
En cas de langue comme le français
Les mots peuvent être classés en ordre alphabétique.
En cas de japonais
C’est bien compliqué…
- ひらがな
- カタカナ
- alphabet
- 漢字
2 types de syllabaires, l’alphabet latin et les kanjis. En outre les kanjis changent leur sons en fonction de contexte.
En effet la ligne de commande « sort » a donné l’ordre comme ci-dessous.

Solution : Précision de la langue
En ajoutant « LANG=ja_JP.Unicode » à la ligne de commande, on peut récupérer le résultat attendu.

Les mots sont bien comptés une seule fois.
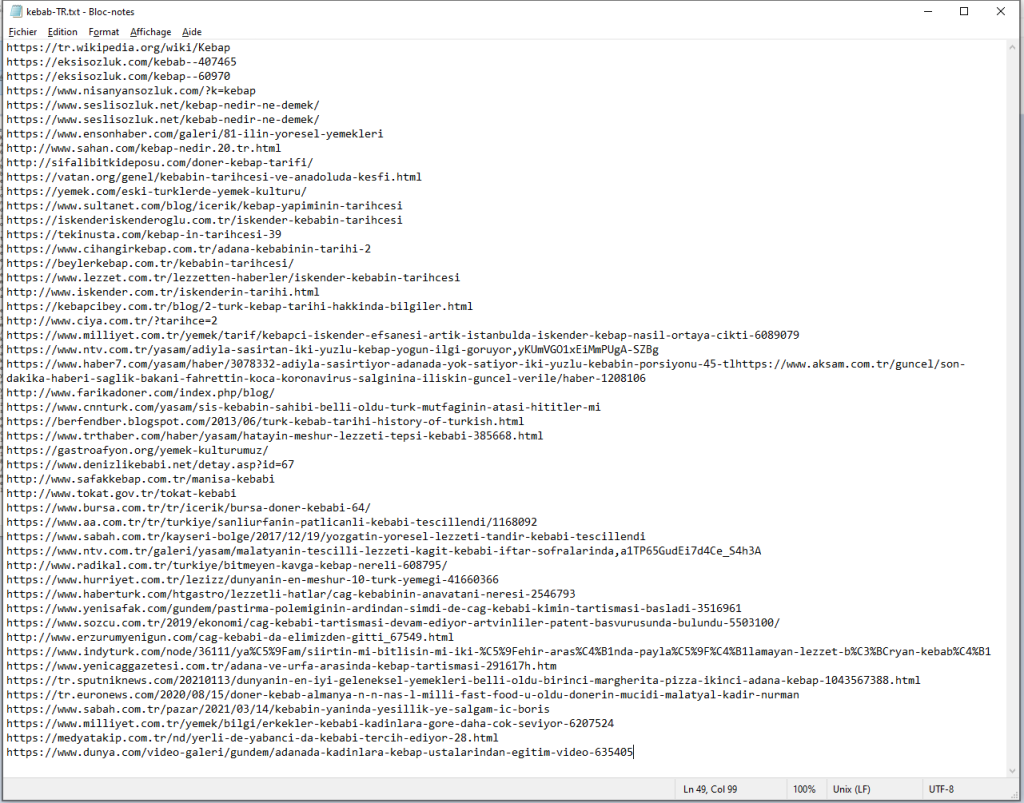
Après un nettoyage des mots, nous avons créé un nuage de mots en japonais et sa traduction en français.


Petite amélioration sur l’encodage :
La ligne de commande curl ne peut pas récupérer l’encodage de tous les sites.

curl is a tool to transfer data from or to a server, using one of the supported protocols (HTTP, HTTPS, FTP, FTPS, GOPHER, DICT, TELNET, LDAP or FILE). The command is designed to work without user interaction.
Manuel : https://www.mit.edu/afs.new/sipb/user/ssen/src/curl-7.11.1/docs/curl.html
-i/–include : (HTTP) Include the HTTP-header in the output. The HTTP-header includes things like server-name, date of the document, HTTP-version and more…
Afin de voir d’où vient la différence des sites avec ou sans encodage, nous avons comparer les deux résultats de la commande « curl -L -I ».

Pour le site avec encodage, curl récupère l’information d’encodage, « charset ».

En revanche, pour le site sans encodage, il n’y a pas de l’information sur « charset ».
Donc on ne peut pas avoir l’encodage avec « curl -L -I ».
Solution :
Récupération de l’encodage à partir de la ligne de html.

Pour les html qui ne sont pas en UTF-8, l’exécution de iconv afin de convertir en UTF-8, puis sed -e pour modifier le html.




Voici le tableau avec l’information encodage complète.